
今后,东航C919将常态化执飞“上海虹桥—武汉天河”,每天一班往返炒股股票配资平台网,去程MU5385航班09:20从上海虹桥国际机场起飞,11:20抵达武汉天河国际机场;返程MU5386航班12:30从武汉天河国际机场起飞,14:00抵达上海虹桥国际机场。(央视新闻)
另据华为门店销售人员透露,首销当天,Mate 70 标准版备货充足,消费者到店即可购买现货。而 Pro 以及其它版本货太少,价格也略高一些。
编辑:桃子 好困
【新智元导读】Scaling Law并未失效,只是不再局限于参数规模的增加。MIT团队最新研究发现,测试时训练在Scaling大模型上,显现出突破性潜力,ARC公共基准测试中拿下61.9%成绩,媲美人类选手。
OpenAI被曝出下代旗舰模型Orion进展缓慢,内部成立团队大改方向,一时间在全网掀起巨大的风暴。
大模型Scaling Law撞墙了、失效了....各种论调甚嚣尘上,OpenAI大牛不得不下场亲自挽救这场被怀疑论淹没的局面。
他们笃定的是,推理/测试时计算(test-time compute),是Scaling大模型另一个「齿轮」。

好巧不巧,MIT团队最新力作又延展了o1 Scaling路线,证明了「测试时训练」(TTT)能够让模型性能暴涨。

论文地址:https://ekinakyurek.github.io/papers/ttt.pdf
TTT能够将1B微调模型的性能,提升高达6倍。
并且,TTT与8B参数模型结合后,在ARC中取得53%准确率,比纯神经网络模型的SOTA提升近25%。

不仅如此,将TTT与程序生成方法集成,更是创下61.9%的最优性能,相当于人类平均得分。

具体来说,研究人员在推理过程中,使用从输入数据中得到的损失函数临时更新模型参数,并在ARC中验证了TTT在提升LLM推理能力上有效性。
他们系统性分析了ARC任务上进行TTT所需的关键组件,并提出了一种新颖的「TTT数据生成」和自洽性(self-consistency)组件。
最终结果表明,配备TTT的大模型,也能够匹敌甚至超越ARC上许多基于显示符号推理模型的性能。
OpenAI研究科学家、德扑之父Noam Brown第一时间转发了新研究,并称我们通过o1开发了一种scale测试时计算的新方法,但它并不是唯一的方法,也可能不是最好的方法。很兴奋可以看到学术研究人员朝着这个方向,探索出新的方法。

OpenAI研究员Jason Wei站在更高层面上,打开了scaling的思路:
当前,拥有完美想法已经不再是关键的因素了。深度学习有很强的灵活性,解决同一问题可能会有多种可行的方法。一旦一个想法基本可行,真正的竞争就在于有多少有实力、有信念且拥有资源的人在做这件事。

GensynAI联创表示,「训练和推理的之间的界限,正加速模糊」。

Scaling大模型新方向:测试时训练
o1发布之后,愈加凸显了使用额外的「测试时计算」增加大模型解码,能够显著提升其性能的重要性。
此类方法,还包括思维链提示、多数投票采样、代码执行、搜索等等。
最近引起普遍关注的另一种扩展策略是「测试时训练」(Test-time training),模型通过基于测试时输入的显式梯度步骤进行更新。
它与标准微调不同之处在于,TTT在极少数据条件下可以运行——通常通过单个输入进行「无监督学习」,或从一两个上下文中标记示例进行「监督学习」。
TTT最初是由UC伯克利、UCSD机构研究人员于2020年在视觉模型中首次提出,并在2022年发表的序列模型中得到应用。

论文地址:https://arxiv.org/pdf/1909.13231
TTT方法的设计空间很大,然而目前对于哪些设计选择对大模型,尤其是新任务学习最有效的了解有限。
由此,MIT团队在最新论文中,系统性研究了各种TTT设计选择的影响,及其与预训练和采样方案的相互作用。
在此过程中,他们确定了TTT有效应用于少样本学习的几个关键要素:
测试时遇到的类似合成任务上进行「初始微调」
采用增强的「留一法」(leave-one-out)任务生成策略来构建测试时数据集
「每个实例」适配器训练和
可逆变换下的「自洽性」
通过这些组件的精选选择,正如我们开篇所见,TTT显著提升了大模型在ARC上的表现。
事实上,研究结果证明了,以前只能通过程序合成解决的任务,配备了TTT框架之后,也可以通过纯神经网络的方法解决。
这些结果挑战了符号组件,是解决此类复杂任务的绝对必要条件这一假设。
相反,在解决新颖推理问题的关键因素可能是在测试时分配适当的计算资源,或许与这些资源是通过符号还是神经机制部署无关。
那么,「测试时训练」是如何定义的?
论文中,研究人员指出TTT在推理过程中,通过动态参数更新进行自适应,这是大模型时代相对未被深入探索的方法。
直白讲,TTT是一种迁移学习的形式,模型利用测试数据结构来改善其预测。
MIT研究人员解释了,测试时训练就是指,在测试时调整模型自身。

另一位论文作者表示,在通过CoT、搜索等Scaling「测试时计算」方面已经取得了很大的进展。在我们的新工作中,我们证明了TTT可以是这个工具包的另一个强大的补充。

Keras之父同样表示,测试时微调,是一种对DL模型中包含的向量函数,进行动态重组以适应新任务的方法。

还有网友解释了o1和TTT区别在于:梯度更新。TTT通过改变模型参数来适应数据,而o1使用内部对话来实现适应。
总之,「测试时」范式革命在于——即时适应能力。

一般的TTT工作原理如下:从初始模型参数θ_0开始,对于每个测试输入(或输入批),首先从测试输入生成训练数据D_TTT(d_input)。
然后,优化这些参数以最小化损失函数L(D_TTT; θ),生成用于预测的临时更新参数θd。
生成预测后,模型恢复到原始参数θ_0,以便处理下一个实例或批次。
因此,TTT为每个测试输入训练一个专门的预测模型,该模型是通过在从该测试输入生成的测试时数据集上微调基础模型获得的。
研究人员考虑到上下文学习设置,会提供更丰富的上下文形式,即示例对(x_1, y_1), ..., (x_K, y_K)。
在这里,应用TTT-FT首先构建一个初始语言模型LM,将每个测试输入x映射到特定于输入的数据集D_TTT,微调LM以根据数据集上的某个损失函数L进行优化:
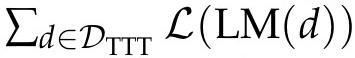
,最后从更新后的模型中采样以获得最终预测。
TTT期间有哪些数据集和损失?
数据生成
给定一个任务,将训练输入输出对
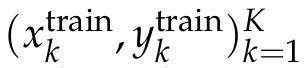
转换为增强的测试时训练任务集(D_TTT)。
研究人员通过一个两步过程获得D_TTT:
首先,从给定的训练输入输出对中,创建一个「留一法」的上下文学习任务集。
其次,对该集合应用可逆的基于规则的转换,以获得增强的数据集。
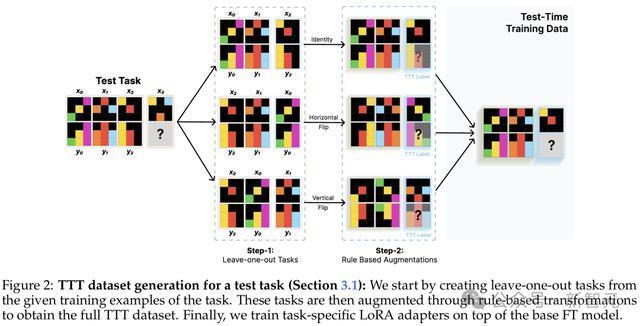
步骤1 - 留一法任务
通过从训练示例中排除第j个示例对,可以创建以下合成任务:
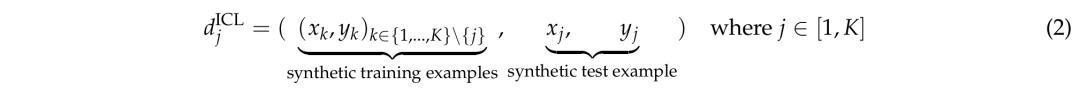
其中d_j是一个合成训练任务,第j个示例对被视为测试案例。在此,可以生成n个不同的任务,每个任务包含n−1个示例对。
步骤2 - 基于规则的转换
考虑一个可逆转换t,使得t^−1(t(x)) = x。对于步骤1中获得的每个任务,可以使用t生成一个新的增强任务
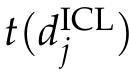
,其中t应用于任务中的每个单独网格。
研究人员选择了简单的转换,这些转换在引入受控变化的同时保留基本关系,例如旋转、翻转、颜色置换、示例置换、尺寸缩放等。最后,获得:
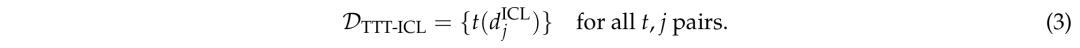
基线 - 端到端学习任务
为了与上述「测试时上下文学习」方法进行比较,研究人员还评估了「测试时端到端学习」方法。
通过将每个输入输出对视为独立的训练实例,直接从示例演示中创建一个监督数据集。
与上下文学习设置不同,不使用上下文进行预测:
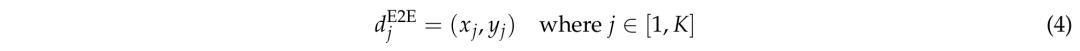
值得注意的是,这相当于ICL设置中「留(n−1)法」任务集,因为没有提供训练示例作为上下文。与ICL情况类似,可以应用基于规则的转换来扩充数据集:
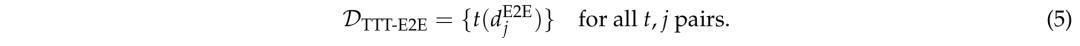
这种方法在计算上更加高效,因为它直接学习输入输出映射,而无需管理示例上下文(即几次提示)的开销。
优化目标
接下来,在TTT期间,研究人员使用LoRA优化了一组特定于任务的参数,同时冻结大部分基础模型。这种方法在保持模型一般能力的同时,还能实现高效适应性计算。
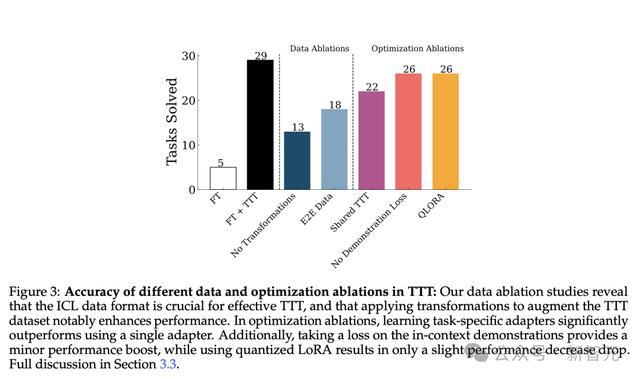
结果如下图3所示,TTT方法将微调模型准确率提高了6倍(从5提高到29)。
另外,使用上下文学习任务明显优于端到端的任务,在相同条件下,显示出出11个任务(38%)的相对性能下降。
研究人员还对TTT优化的多个组件进行消融实验,来分析其对性能的贡献。
在所有任务中使用单个LoRA适配器,会降低7个任务的性能(降低24%)。
这是符合预期的,因为使用专用适配器允许每个任务训练更多参数。
其次,他们在输出示例上采取损失的决定略微改善了性能(26提升到29),这是因为它迫使模型在处理示例时思考转换。
最后,研究人员还观察到使用量化LoRA(QLoRA)仅导致性能略微下降(29降到26)——在内存受限的情况下,使用QLoRA可能是可行的。
TTT后推理策略是什么?
增强推理
推理时Scaling替代方案是什么?
研究人员对此采用一种增强推理策略,通过几何变换生成多个预测候选方案,并结合贪婪解码方案。
对于给定的任务,其中包含训练样例
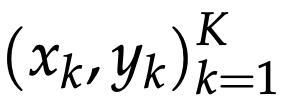
和测试输入x_test,研究人员使用可逆的几何变换来生成任务的等效变换版本,如上图3所示。
假设T是一组可逆几何变换的集合(例如,旋转和反射)。
对于每个变换t∈T,研究人员将t应用于所有训练示例和测试输入,并使用这些变换后的输入运行模型。
然后,应用逆变换来获得该变换的最终预测。
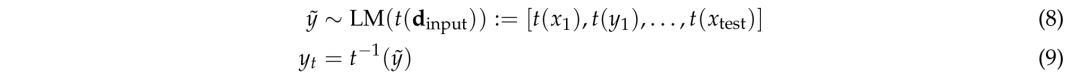
之后,研究人员通过打乱训练示例的顺序来进一步增强预测。对于每个变换g,他们对示例序列采样n=2个不同的排列,从而为每个任务产生n·|T|个总预测。
这是为了减轻模型在处理示范序列时的任何偏差。
集成预测(投票策略)
这一方法涉及了两阶段的投票,以逐步缩小最佳候选
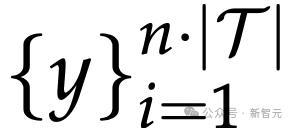
的范围:
1. 转换内部投票(Intra Transformation Voting)
首先按照转换类型t对预测结果进行分组,在组内选择出现频率最高的TOP 3预测。
如果一个组内独特预测少于3个,会通过以下方式补充候选项:基于行的多数,以及基于列的多数。
2. 全局投票(Global Voting)
使用第一阶段得到的特定转换候选项进行整体投票,选出出现频率最高的前2个预测作为最终提交结果。
如果出现平局,优先选择恒等转换(identity transformation)的预测。
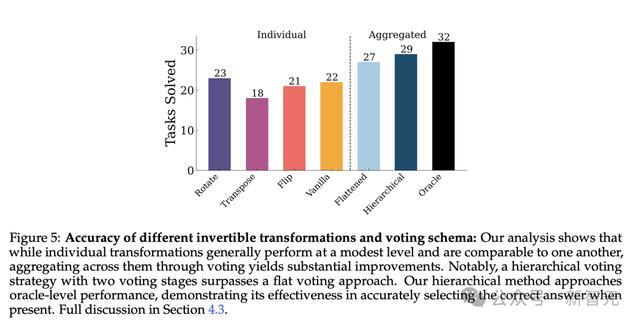
结果如图5所示,单独使用特定的转换版本,性能普遍较差。其中,转置(transpose)的转换准确率最低。
通过投票程序将这些转换结果进行聚合后,性能得到显著提升,而且使用自洽性(self-consistency)投票进行聚合通常是有益的,这个发现与之前的研究结果一致。
此外,扁平化投票程序(flattened voting)能提高准确率,分层投票程序(hierarchical voting)表现更优,超越了前者。
TTT前要微调什么?
准备微调数据
1. 使用现有生成器
REARC中的生成器函数gs已经通过为相同任务生成不同实例提供了一种有效的数据增强工具。
可以通过多次运行生成器代码并随机将这些新示例(d∼eval(g_i))分割为训练和测试示例集,从这些训练任务中生成额外样本。
2. 少样本提示大模型
在利用模型生成新任务时,最简单的方法是通过少样本示例生成新的任务生成器:
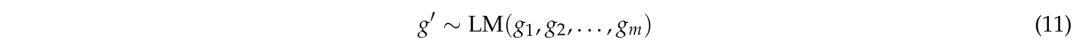
其中,g′是一个新的生成器函数,g_1,…,g_m是现有生成器函数(如图6所示)。

从现有训练集中均匀采样不同的m个示例,并多次重复此过程以获得大量任务。然后,通过任务描述增强生成器函数,并联合生成描述和生成器:
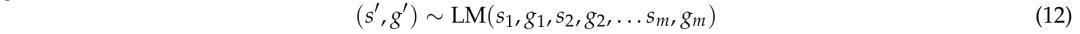
其中,si代表任务i的描述。
为了获得任务描述,研究人员手动为10个训练任务创建了种子描述。这些种子描述随后通过少样本提示生成训练和验证任务的描述。为了增加任务多样性,研究人员使用了包含层次字段(类别、摘要和描述)的任务描述。
除了联合生成任务描述和函数生成,研究人员还采用了如下所述的两阶段方法:
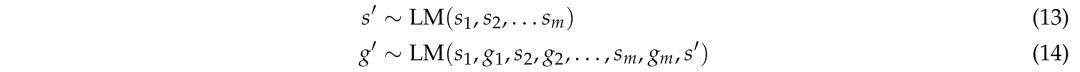
这种方法首先生成一个任务描述s′,然后在现有任务对和新描述的基础上进行生成器创建。
通过这些基于大模型的方法,研究人员共收集了6426个生成器。图11展示了这些语言模型生成任务的定性样本。
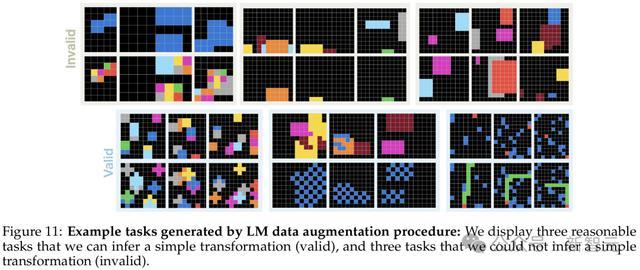
3. 几何变换
最后,这些合成任务通过各种几何变换得以增强,例如基本变换(旋转、反射、随机位移和尺寸缩放)、模式操作(随机拼接、平铺和重复)、颜色置换以及顺序应用多个基本变换的复合变换。
这些变换通过三种方式应用:
- 仅输入网格:(x,y)→(t(x),y)
- 仅输出网格:(x,y)→(x,t(y))
- 输入和输出均变换:(x,y)→(t(x),t(y))
微调数据如何影响TTT性能?
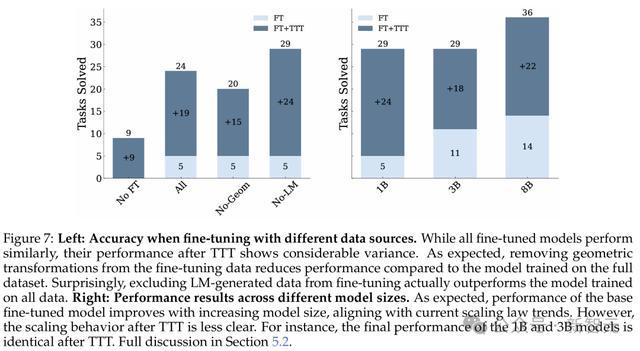
研究人员在图7中,比较了使用不同微调数据的模型。
结果发现,使用REARC和基于规则的增强训练的模型表现最佳。
令人惊讶的是,包含LM生成的任务导致性能下降了5%,这表明当前基于LM的任务生成方法可能需要更复杂的过滤机制。
最后,他们还发现微调性能与TTT性能几乎没有相关性。
模型大小和TTT Scaling
图7中还展示了不同模型大小的结果。增加模型大小持续提高微调性能,其中8B模型取得了36%最高准确率。
研究人员还观察到TTT有效地弥合了较小模型的性能差距,1B和3B模型在应用TTT后达到了相似的准确率。
ARC基准以及与其他系统比较
测试时训练影响
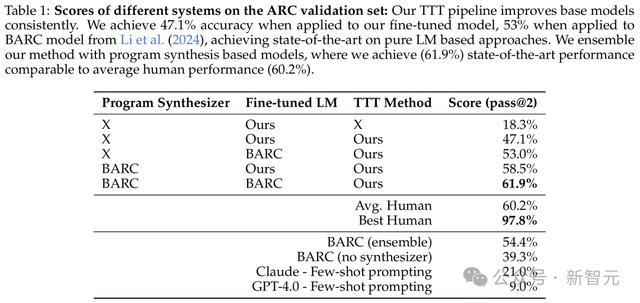
研究人员将TTT方法和推理程序应用到基础微调模型(8B微调模型没有使用任何LM数据)。结果表明,TTT将准确率从39.3%提高到47.1%,超越了现有的端到端神经模型结果。
与现有方法集成
BARC通过结合神经网络和程序合成方法实现了54.4%的准确率。虽然这两种方法有相似之处,但TTT和推理管线有几个额外的组件可以提升性能。
特别是,研究人员提出的测试时训练包括每个任务的LoRA和更大范围的增强,而预测管线包括在可逆变换下进行的增强推理和层次化自洽性投票机制。
结果显示,最终配置在ARC公共评估集上凭借这61.9%的准确率刷新了SOTA——与人类平均表现的60.2%相当,但仍低于最佳的97.8%。
程序生成和端到端建模比较
此前研究发现,即使在相同任务上训练,程序合成和完全神经网络预测器对于ARC来说是高度互补的。
端到端神经模型只能解决,程序合成模型所能解决任务的42.2%。
然而,研究人员发现,当配备TTT架构时,BARC微调的完全神经网络模型解决了程序合成模型解决的任务的73.5%。
这表明,TTT显著提高了神经模型学习系统性推理模式的能力,这与程序合成模型所捕获的模式类似。
在论文最后局限性中,有一个值得注意的点是:数据泄露。
尽管Llama 3在公开验证集中表现较差,但数据集在多个公开平台(如GitHub、Kaggle)上可获得,或许已被用于模型的训练过程。
因此,数据泄露可能会导致模型性能被高估。
结论
这项工作证明,测试时训练可以显著提升在广泛使用的ARC数据集上的LM性能,同时学习任务特定的LoRA适配器和使用几何变换生成增强的测试时数据集至关重要。
此外,研究人员还开发了一种通过使用可逆变换生成多个预测,然后使用自洽性选择最佳候选项的增强推理管线。整体管线应用了多种测试时计算方法,每个组件都产生了积极的贡献。
这表明,不仅测试时计算可以提高LM性能,不同的测试时方法也可以相互补充。
结果显示,新的TTT管线结合了现有方法(BARC),在ARC公共集上实现了最先进的结果,并与人类平均水平60.2%相当。
总而言之,测试时方法可能在推动下一代LM的发展中发挥关键作用。
参考资料:
https://x.com/akyurekekin/status/1855680785715478546炒股股票配资平台网